设计架构图
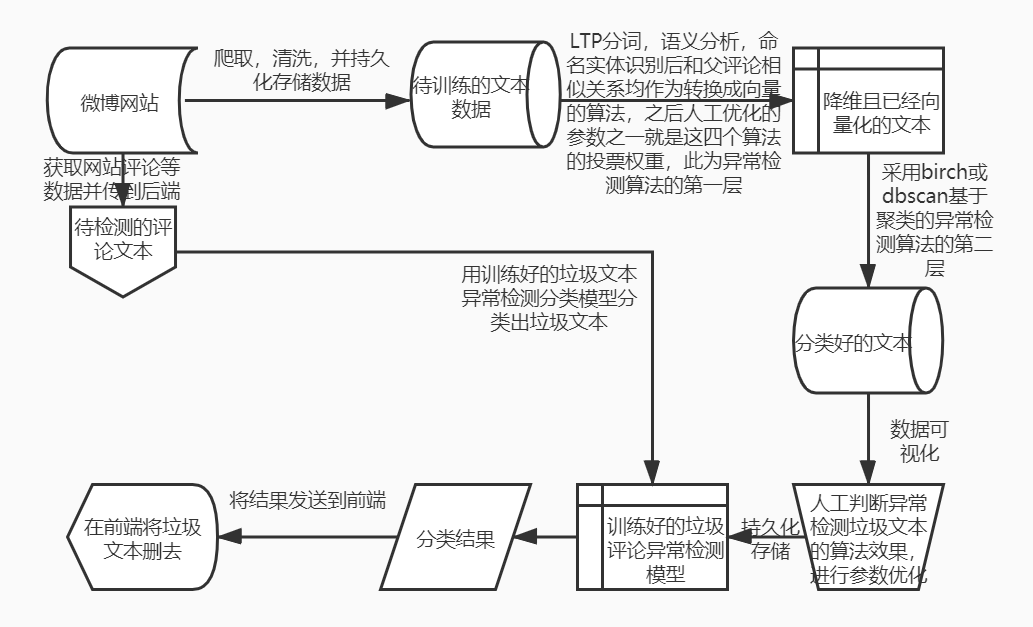
上述内容实现以后,可以优化的地方是
爬取,清洗,持久化存储数据
省略部分细节,例如对数据库的 合并,拆分 等。
不喜求喷。
利用selenium获取进入评论网页的链接
进入 https://m.weibo.cn/ 后,不断将网页向下滚动,获取动态加载的内容,利用redis的set去重,最后获得两种有用的链接。一种形如 /detail/213113123123124,一种是包含中文字符的链接(例如:https://m.weibo.cn/search?containerid=231522type%3D1%26t%3D10%26q%3D%23%E6%88%91%E7%9A%84%E5%B0%8F%E7%A1%AE%E5%B9%B8%23&isnewpage=1&luicode=10000011&lfid=102803),需要进入链接对应网页后点击首个评论,之后链接便转换为前者。
由于 链接地址从前者映射到后者 是js动态生成的,而js源码又看得我脑阔疼,也看不出。所以之后通过selenium将后者转换为前者,之后合并两份链接,统一处理。
链接获取(code)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
from selenium import webdriver
import time
import re
from lxml import etree
import redis
option = webdriver.ChromeOptions()
option.add_argument(r'--user-data-dir=D:\ChromeUserData')
wd = webdriver.Chrome(r'd:\chromedriver.exe', options=option)
wd.implicitly_wait(5)
wd.get('https://m.weibo.cn/')
wd.maximize_window()
scrapied = set()
detail_link = []
time.sleep(2)
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
while True:
wd.execute_script("window.scrollBy(0,3000)")
TIMES = TIMES + 1
html = wd.page_source
selector = etree.HTML(html)
list_m = selector.xpath('//*[@id="app"]/div[1]/div[2]/div[2]/div')
print(len(list_m))
for raw_link in list_m:
link = raw_link.xpath('./div/div/article/div/div/div[1]/a/@href')
if len(link) >= 1:
link = link[0]
else:
link = None
link = str(link)
if re.match('/status', link):
r.sadd('detail', link.split('/')[2])
elif len(link.split('/')) > 3 and link.split('/')[2] == "m.weibo.cn":
r.sadd('complex', link)
else:
print(link)
wd.execute_script("window.scrollBy(0,6000)")
time.sleep(2)
|
效果二瞥

链接转换(code)
写得很丑,三个账号轮流切换,操纵js点击,数据解析,都在中间件里了,其它地方的代码不贴了,理解万岁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
def process_response(self, request, response, spider):
print("spider.which_option: " + str(spider.which_option) + " num: " + str(spider.p_num)+ " remain: " +
str(spider.r.scard("union_3_9")) + " no_button_or_formatted: " + str(spider.no_button))
if spider.p_num % 34 == 0:
print("sleeping...")
sleep(1000)
if spider.p_num % 10 == 0:
print("have scrapped: " + str(spider.p_num))
if spider.which_option == 2:
spider.bro.quit()
option2 = webdriver.ChromeOptions()
option2.add_argument(r'--user-data-dir=D:\ChromeUserData2')
spider.bro = webdriver.Chrome(r'd:\chromedriver.exe', options=option2)
spider.bro.implicitly_wait(5)
spider.bro.get(request.url)
spider.which_option = 1
elif spider.which_option == 1:
spider.bro.quit()
option1 = webdriver.ChromeOptions()
option1.add_argument(r'--user-data-dir=D:\ChromeUserData1')
spider.bro = webdriver.Chrome(r'd:\chromedriver.exe', options=option1)
spider.bro.implicitly_wait(5)
spider.bro.get(request.url)
spider.which_option = 0
else:
spider.bro.quit()
option = webdriver.ChromeOptions()
option.add_argument(r'--user-data-dir=D:\ChromeUserData')
spider.bro = webdriver.Chrome(r'd:\chromedriver.exe', options=option)
spider.bro.implicitly_wait(5)
spider.bro.get(request.url)
spider.which_option = 2
else:
spider.bro.get(request.url)
sleep(2)
try:
button = spider.bro.find_element_by_xpath(
'//*[@id="app"]/div[1]/div[1]/div[4]//div/footer/div[2]/i | //*[@id="app"]/div[1]/div[1]/div[5]//div/footer/div[2]/i')
except:
button = None
if button:
spider.bro.execute_script('arguments[0].click();', button)
else:
try:
print(spider.bro.find_element_by_xpath('/html/body/div/p/text()').extract_first())
exit()
except:
print("no button")
spider.r.srem(spider.db_c, request.url)
spider.r.sadd('no_button', request.url)
spider.no_button = spider.no_button + 1
return response
sleep(2)
spider.p_num = spider.p_num + 1
link = str(spider.bro.current_url)
ll = link.split('/')
if len(ll) >= 5 and ll[3] == 'detail':
spider.r.sadd('c_detail', ll[-1])
spider.r.srem(spider.db_c, request.url)
print("spider.bro.current_url: " + link)
else:
# 这里直接从数据库中删掉
spider.r.srem(spider.db_c, request.url)
spider.no_button = spider.no_button + 1
print(link)
return response
|
效果不瞥
![不瞥]()
获取评论
以逸待劳
没钱,没IP,没账号,~~没脑子,~~只能sleep。。。
所谓sleep,就是电脑跑,我躺。
因为微博爬的稍微多一点就会被限制,然后就要等个10到20分钟才能继续爬,所以scrapy那个异步的玩意儿没用,异到一半给你个403,然后你还得保留一群没异完的数据来知道自己上次爬到哪儿了,代码量杠杠的,头发萧萧的,效率提升可怜,还不如给爷一个个链接爬,在数据解析那一块直接持久化存储,爬了遇到不是200的,直接一个sleep。当然,可以切换个cookie,或搞两个代理ip试试,如果搞代理的钱给报销就好了,可惜报不得。。爬到结尾遇到ok=0了,说明一条数据完了,把爬过的id在数据库中删掉,相当于保存状态,然后继续下一条。不让它异步,把CONCURRENT_REQUESTS设置为1,感觉拿个框架搞这个有点像高射炮打蚊子。微博需要手机验证码登录真的恶心(比淘宝拿深度学习搞稍微好点),虽然之后搞个cookie可以解决,鬼想去看源码分析cookie中有没有键是通过时间来验证的,就像有道字典网页版的cookie一样,虽然直接复制cookie在之后爬【被评论的文本】确实有效果。
微博账号|手机号 少,代理IP仅限翻墙用的VPN,我甚至想 搞个 多个热点、一个wifi、一个VPN 自动切换的脚本,但理智与对自己精力与实力清醒的认识让我放弃了这个冲动。
人生不易,躺平: 以逸待劳
爬取清洗并持久化存储被评论的文本信息(code)
开始用 requests 做试验,然后 scrapy 实现,结果同样的思路,scrapy 中除了多了这个场景不需要的异步,还出现了一个很诡异的问题,估计是我 cookie 设置没有生效,爬到一半又是弹出登录界面,不过这个报错我 requests 中没遇到过,暂且将这个错误情况收入囊中,给之后的 requests 用。scrapy 框架是死的,requests 库是活的,所以 评论的爬取与持久化存储 用 requests 了。
写这玩意儿花了我将近一天时间,呜~ 数据量越大,边界条件越复杂,真是【if else try catch 地狱】啊!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
import requests
import re
import redis
import json
from time import sleep
db_key = 'copy_all'
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
"cookie": "WEIBOCN_FROM=1110006030; SUB=_2A25NEV0tDeRhGeBL7lYY9ybFyDiIHXVu-mNlrDV6PUJbkdAKLXbwkW1NRutLlmTowwVwMFvx2VGceNikaFWGhsY8; MLOGIN=1; _T_WM=67795908980; M_WEIBOCN_PARAMS=oid%3D4598439113919494%26luicode%3D20000061%26lfid%3D4598439113919494%26uicode%3D20000061%26fid%3D4598439113919494; XSRF-TOKEN=657a72"
}
be_cf_url = "https://m.weibo.cn/detail/{}"
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
id_pool = r.smembers(db_key)
continous = 0
cannot_sum = 0
interval_controller = 1
headertimes = 1
for u_id in id_pool:
interval_controller += 1
if interval_controller % 97 == 0 or headertimes % 11 == 0:
print("sleeping......")
headertimes = 1
interval_controller += 1
sleep(1000)
continous = 0
be_c_url = be_cf_url.format(u_id)
be_res = requests.get(url=be_c_url)
if be_res.content and be_res.status_code == 200:
bec_l = re.split(r'"text":|"textLength":|"source":', be_res.text)
if len(bec_l) < 2:
print('now that I use headers')
headertimes += 1
be_res = requests.get(url=be_c_url, headers=headers)
if be_res.content and be_res.status_code == 200:
bec_l = re.split(r'"text":|"textLength":|"source":', be_res.text)
else:
print("how come??? " + be_c_url)
exit()
if len(bec_l) < 2:
print("napping...")
print("odd: " + be_c_url)
r.sadd("odd_link", u_id)
with open('assert_login_required.html', 'w+', encoding='utf-8') as f:
f.write(be_res.text)
sleep(4)
continue
else:
be_emoji_contents = bec_l[1] # 1 big
be_emoji = re.findall(r'alt=\[(.+?)\]+', be_emoji_contents)
be_contents = re.findall(r'[\u4e00-\u9fa5]+', be_emoji_contents)
author = re.split(r'"profile_image_url":|"screen_name":', be_res.text)[1].strip()[1: -2]
be_co_list = re.split(r'"reposts_count":|"comments_count":|"attitudes_count":|"pending_approval_count":', be_res.text)
be_co_retweet = re.findall(r'\d+', be_co_list[-4])[0]
be_co_comments = re.findall(r'\d+', be_co_list[-3])[0]
be_co_like = re.findall(r'\d+', be_co_list[-2])[0]
be_emoji_ser = '|'.join(be_emoji)
be_contents_ser = '|'.join(be_contents)
obj = {"id": u_id, "be_co_retweet": be_co_retweet, "be_co_comments": be_co_comments,
"be_co_like": be_co_like, "author": author, "be_emoji": be_emoji_ser, "be_contents": be_contents_ser}
value = json.dumps(obj)
if r.hset("vb_article", u_id, value):
print("remain: " + str(r.scard(db_key)) + " | done: " + str(interval_controller - 1) + " | odd_link: " + str(r.scard("odd_link")) + " | saving -> ")
print(value)
else:
print("remain: " + str(r.scard(db_key)) + " | done: " + str(interval_controller - 1) + " | odd_link: " + str(r.scard("odd_link")) + " | duplicated -> ")
print(value)
r.srem(db_key, u_id)
else:
try:
print(be_res.text)
print("的确把我禁了,呜——")
except:
print("WTF?!")
print(be_res)
exit()
|
效果一瞥
还在爬,先瞥了。
爬取并持久化存储评论别人的文本信息(code)
这个数据量更大,花半天写完后,就让它跑了。测试了总共有100个id左右,爬了两万多条评论,感觉可以了,就开始漫长的跑爬虫了。不出意外的话,估计跑1天可以拿到40万条评论。让我们拭目以待。
这玩意儿跑这么长时间只能拿到这么一点数据主要是我账号太少了,只有3个。让我不得不在代码中精打细算,还好没加入保存长得号对应的状态,我试着写过,写到200多行就不敢继续写了,到时候debug不知得花多久时间,不如直接进行下一个链接,把上一个可能爬到一半的放到最后再去爬。
如果给我的账号数量增加1000倍,也就是给我3000个cookie和UA组(没看源码,估计它的加密涉及UA,所以UA和cookie要对应),增量式,把微博的评论一直爬完,,,不是问题。可惜有不得。
爬到20多万条数据时,出现了证书出错的情况。这个错误给我的感觉是随机发生的。代码有改动。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
|
import requests
import json
from time import sleep
import redis
# import urllib3
# urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
def dialog(n, t, l, m, c):
with open('{level}_dialog_{name}.{type}'.format(name=n, type=t, level=l), '{method}'.format(method=m),
encoding='utf-8') as f:
f.write(c)
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
db_id = "copy_all"
out = "out4"
db_store_comments = "comment_raw"
headers = [
{
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36",
"cookie": "WEIBOCN_FROM=1110006030; SUB=_2A25NEV0tDeRhGeBL7lYY9ybFyDiIHXVu-mNlrDV6PUJbkdAKLXbwkW1NRutLlmTowwVwMFvx2VGceNikaFWGhsY8; MLOGIN=1; _T_WM=67795908980; M_WEIBOCN_PARAMS=oid%3D4598812490338528%26luicode%3D20000061%26lfid%3D4598812490338528; XSRF-TOKEN=6ccdfa"
},
{
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
"cookie": "SUB=_2A25NCGyZDeRhGeFL7lYW8ifKyjuIHXVu83TRrDV6PUJbkdAKLXftkW1NfedyhZeSJiB2FIIkBxvJsYliT6pqVB5r; _T_WM=51270776894; MLOGIN=1; WEIBOCN_FROM=1110006030; M_WEIBOCN_PARAMS=luicode%3D10000011%26lfid%3D102803%26uicode%3D10000011%26fid%3D102803; XSRF-TOKEN=7b2f74"
},
{
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
"cookie": "SUB=_2A25NEfqWDeRhGeFN61EZ8C3FzzuIHXVu_YberDV6PUJbkdANLWelkW1NQJzKAyjB5YSsbaRBCtwFYN7bdNCHez3d; _T_WM=99361324838; XSRF-TOKEN=2da516; WEIBOCN_FROM=1110006030; MLOGIN=1; M_WEIBOCN_PARAMS=luicode%3D20000174%26uicode%3D20000174"
}
]
common_url = "https://m.weibo.cn/detail/{}"
start_get_uormat = "https://m.weibo.cn/comments/hotflow?id={id}&mid={id}&max_id_type=0"
next_ajax_uormat = "https://m.weibo.cn/comments/hotflow?id={id}&mid={id}&max_id={max_id}&max_id_type={max_id_type}"
url_pool = list(r.smembers(db_id))
next_url_flag = False
hi = 1
luck = 0
for url_id in url_pool:
cur_url = start_get_uormat.format(id=url_id)
break_big = False
try:
res = requests.get(url=cur_url, headers=headers[hi]) #, verify=False
except:
print("证书失效1")
break_big = True
cnum = 0
exp = 0
next_url = None
while True:
if break_big:
break
tries = 0
sp = 0
# turn = 0
# get res_text or give up
while tries < 3 and sp < 5:
'''
sp: 403 || 200 but have not got content
tries: comments load complete or I give up
'''
if res.status_code == 200 and res.content: # 分开?
try:
exp = 0
res_text = json.loads(res.text)
except:
if next_url:
print("maybe login required and need to change cookie or just sleep " + next_url)
else:
print("maybe login required and need to change cookie or just sleep " + cur_url)
dialog(n=url_id, m='w+', l='f_error', c=res.text, t='html')
print(hi)
tries += 1
exp += 1
sleep(2 ** (tries - 1))
if exp > 3:
exp = 0
print("long sleep...............")
sleep(1000)
# exit()
if str(res_text['ok']) == "0":
tt = 2 ** tries
sleep(tt)
tries += 1
try:
if next_url:
print("wait: " + str(tt) + " | " + "response json content may be incomplete: " + next_url)
res = requests.get(url=next_url, headers=headers[hi]) #, verify=False
else:
print("wait: " + str(tt) + " | " + "response json content may be incomplete: " + cur_url)
res = requests.get(url=cur_url, headers=headers[hi]) #, verify=False
except:
print("证书失效2")
break_big = True
break
else:
break
else: # 这种情况大概率是请求频繁了
if next_url:
print("tries: " + str(tries) + " times | problem: " + next_url)
else:
print("tries: " + str(tries) + " times | problem: " + cur_url)
luck += 1
if luck <= 2:
print("snap a luck, drop header: " + str(hi))
sleep(2 ** (luck - 1))
elif luck < len(headers) + 2:
# turn += 1
hi += 1
hi %= len(headers)
break_big = True
break
else:
print("sleep long for luck......")
print("current headers: " + str(hi))
print("done: " + str(2648 - r.scard(db_id)) + " | comments: " + str(
r.hlen(db_store_comments)) + " | remain: " + str(r.scard(db_id)) + " | ")
luck = 0
sleep(1000 - len(headers))
if sp > 4:
print("这还请求频繁?小喇叭!")
print(hi)
print("done: " + str(2648 - r.scard(db_id)) + " | comments: " + str(
r.hlen(db_store_comments)) + " | remain: " + str(r.scard(db_id)) + " | ")
exit()
sp += 1
else:
if next_url:
print("ok, I give up: " + next_url)
else:
print("ok, I give up: " + cur_url)
r.srem(db_id, url_id)
break
if break_big:
break
try:
data = res_text["data"]
data_list = data["data"]
except:
dialog(n=url_id, m='w+', l='u_error', c=res.text, t='html')
print("unexpected response: " + next_url)
print(hi)
exit()
for comment in data_list:
user_id = comment['user']['id']
comment_id = comment['id']
comment_key = str(user_id) + "|" + comment_id
obj = {
"comment_text": comment['text'],
"comment_obj_id": url_id,
"nickname": comment['user']['screen_name'],
"like_count": comment['like_count'],
"reply": comment['total_number']
}
str_obj = json.dumps(obj)
dialog(n=out, l="print", t="txt", m="a+", c=comment_key + '\n' + str_obj + '\n\n')
r.hset(db_store_comments, comment_key, str_obj)
cnum += len(data_list)
print(str(cnum) + " | " + common_url.format(url_id))
max_id = data["max_id"]
if str(max_id) == "0":
print("complete")
r.srem(db_id, url_id)
break
else:
next_url = next_ajax_uormat.format(id=url_id, max_id=max_id, max_id_type=data["max_id_type"])
try:
res = requests.get(url=next_url, headers=headers[hi]) #, verify=False
except:
print("证书失效3")
break_big = True
break
if break_big:
print("regardless status, new link please")
sleep(4)
url_pool.append(url_id)
else:
print("done: " + str(2648 - r.scard(db_id)) + " | comments: " + str(r.hlen(db_store_comments)) + " | remain: " + str(r.scard(db_id)) + " | ")
print("next url please...")
|
效果半瞥
先忍不住放爬了1小时左右时候的截图。
数据处理
数据库设计
数据项(data item)
以hash形式储存在redis中,以前三个id的组合为key。
| key |
value |
| comment_id |
该条评论的 ID |
| user_id |
发出该条评论的 用户ID |
| url_id |
该评论评论对象 对应的 网页ID |
| comment_text |
该评论的 所有中文文本,包括表情指代词 |
| comment_emoji |
该评论的 表情指代词(依次顺序出现在comment_text中) |
| nickname |
该评论作者 在发出这条评论时所用昵称 |
| like_count |
该条评论的 被 点赞的次数 |
| reply_count |
该条评论的 被 回复的次数 |
| be_co_retweet |
该评论评论对象 被 转发的次数 |
| be_co_comments |
该评论评论对象 拥有的评论量 |
| be_co_like |
该评论评论对象 被点赞的次数 |
| author |
该评论评论对象的 用户名 |
| be_contents |
该评论评论对象的 所有中文文本 |
| be_emoji |
该评论评论对象的 表情指代词(依次顺序出现在comment_text中) |
数据库连接与存储(code)
实现上述模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
import redis
import re
import json
def str_to_json_articles(article_str):
o_article = json.loads(article_str)
be_contents = o_article['be_contents'].split('|')
be_emoji = o_article['be_emoji'].split('|')
o_article['be_contents'] = be_contents
o_article['be_emoji'] = be_emoji
return o_article
def str_to_json_comments(comments_str):
o_comment = json.loads(comments_str)
comment = o_comment['comment_text']
comment_emoji = re.findall(r'alt=\[(.*?)\]', comment)
comment_text = re.findall(r'[\u4e00-\u9fa5]+', comment)
o_comment['comment_text'] = comment_text
o_comment['comment_emoji'] = comment_emoji
return o_comment
def obj_to_string(ots):
r_o = {}
for key, value in ots.items():
r_o[key] = '|'.join(value) if isinstance(value, list) else value
# print(r_o)
return json.dumps(r_o)
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
read_articles = 'vb_article'
read_comments = 'comment_raw'
write_comments = 'comments_zh'
t_hash = r.hgetall(read_comments)
articles = r.hgetall(read_articles)
for key, value in t_hash.items():
[user_id, comment_id] = key.split('|')
comment_obj = str_to_json_comments(value)
url_id = comment_obj['comment_obj_id']
articles_str = articles[str(url_id)]
articles_obj = str_to_json_articles(articles_str)
obj = {
"comment_text": comment_obj["comment_text"],
"comment_emoji": comment_obj["comment_emoji"],
"nickname": comment_obj["nickname"],
"like_count": comment_obj["like_count"],
"reply_count": comment_obj["reply"],
"be_co_retweet": articles_obj["be_co_retweet"],
"be_co_comments": articles_obj["be_co_comments"],
"be_co_like": articles_obj["be_co_like"],
"author": articles_obj["author"],
"be_contents": articles_obj["be_contents"],
"be_emoji": articles_obj["be_emoji"]
}
s_keys = '|'.join([comment_id, user_id, comment_obj["comment_obj_id"]])
s_value = obj_to_string(obj)
r.hset(write_comments, s_keys, s_value)
|
异常检测算法第一层
算法选择
已复现网络与论文上的算法评测代码,了解无监督聚类异常检测算法的原理与发展情况,核心代码和实现可参考我的读书笔记。
划分任务(弃用)
提需求,做自己的产品经理
实现需求
语料库要尽量包含所有的词
先用小数据集模拟,避免大数据集运行时间过长
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|
import redis
import json
import jieba
import jieba.analyse
import time
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import PCA
corpus_file = "idf.txt.big" # "idf.txt.big"
stop_words = open("stopWords.txt", encoding='utf-8').read()
corpus_fp = open(corpus_file, 'a+', encoding='utf-8')
raw_corpus = open(corpus_file, encoding='utf-8').readlines()
topK = 10
def remove_stop_words(data_list):
word_list = []
for data in data_list:
if data not in stop_words:
word_list.append(data)
return word_list
def preheat_cache(db, sensitivity=4):
"""
preheat 分词引擎
add new words if discovered from comments,
everytime service started, traversal the database, add new words to cache
takes long time...
wish astringency
"""
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
jieba.analyse.set_idf_path(corpus_file)
raw_comment = r.hgetall(db)
raw_new_words_hash_map = {}
start_time1 = time.time()
for key, raw_value in raw_comment.items():
value = json.loads(raw_value)
comment_text = value['comment_text']
comment_array = comment_text.split('|')
comment = []
for text in comment_array:
# comment.append('/'.join(jieba.cut(text)))
comment.append('/'.join(jieba.analyse.extract_tags(text, topK=topK)))
comment_row = '/'.join(comment)
no_stop_words = remove_stop_words(comment_row.split('/'))
for word in no_stop_words:
if word in raw_new_words_hash_map:
raw_new_words_hash_map[word] = raw_new_words_hash_map[word] + 1
else:
raw_new_words_hash_map[word] = 0
jieba.add_word(word)
print('add new words finished')
new_words_hash_map = {}
for key_word, times in raw_new_words_hash_map.items():
if times >= sensitivity:
new_words_hash_map[key_word] = times
end_time1 = time.time()
print("cost " + str(end_time1 - start_time1))
append_corpus(new_words_hash_map)
def append_corpus(new_words):
corpus = set()
size = len(new_words)
for item in raw_corpus:
w = item.split(' ')[0]
corpus.add(w)
print(len(corpus))
for key_word, times in new_words.items():
if key_word not in corpus and len(key_word) > 2:
new_item = '\n' + key_word + " " + str(topK) # str(times/size)
print(new_item)
corpus_fp.write(new_item)
def text_to_matrix():
"""
according to
https://stackoverflow.com/questions/57507832/unable-to-allocate-array-with-shape-and-data-type
run:
echo 1 > /proc/sys/vm/overcommit_memory
"""
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
tf_idf = transformer.fit_transform(vectorizer.fit_transform(raw_corpus))
weight = tf_idf.toarray()
print(weight)
return weight
def dimension_PCA(weight, dimension):
pca = PCA(n_components=dimension)
X = pca.fit_transform(weight)
print(X)
return X
if __name__ == '__main__':
# print(remove_stop_words(['首先', '你好', '难道说']))
# preheat_cache("comments_zh") # comments_zh
weight = text_to_matrix()
dimension_PCA(weight, dimension=800)
# print(raw_corpus)
|
第一次运行结果
点击下载
第二次运行结果
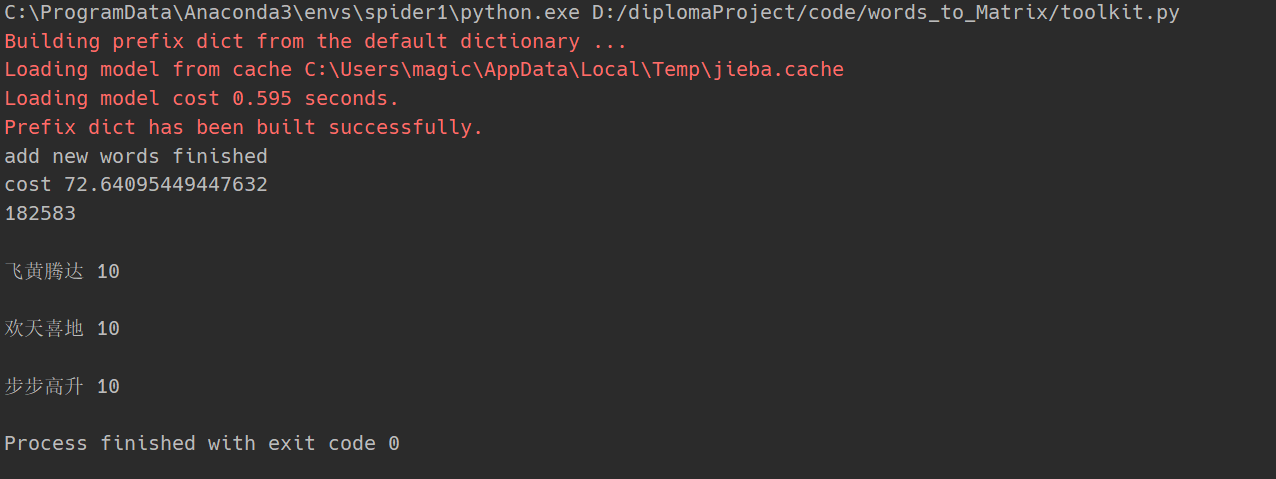
结果总结
语料库会随着爬取评论的增多而扩大,且收敛效果好。可以自适应不断扩大的评论数量。缺点是不能增量式的扩大,每次需要遍历整个语料库,存在重复计算,在服务器架构不优化的情况下,每次服务启动时初始化(预热阶段)的速度会不断变慢,虽然之后的响应速度几乎不变。
继续实现需求
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
|
import redis
import json
import jieba
import jieba.analyse
import time
import torch
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import PCA
from sklearn.cluster import Birch
corpus_file = "idf.txt.big" # "idf.txt.big"
stop_words = open("stopWords.txt", encoding='utf-8').read()
corpus_fp = open(corpus_file, 'a+', encoding='utf-8')
raw_corpus = open(corpus_file, encoding='utf-8').readlines()
topK = 10
def remove_stop_words(data_list):
word_list = []
for data in data_list:
if data not in stop_words:
word_list.append(data)
return word_list
def preheat_cache(db, sensitivity=4):
"""
preheat 分词引擎
add new words if discovered from comments,
everytime service started, traversal the database, add new words to cache
takes long time...
wish astringency
"""
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(host='localhost', port=6379, decode_responses=True)
jieba.analyse.set_idf_path(corpus_file)
raw_comment = r.hgetall(db)
raw_new_words_hash_map = {}
start_time1 = time.time()
for key, raw_value in raw_comment.items():
value = json.loads(raw_value)
comment_text = value['comment_text']
comment_array = comment_text.split('|')
comment = []
for text in comment_array:
# comment.append('/'.join(jieba.cut(text)))
comment.append('/'.join(jieba.analyse.extract_tags(text, topK=topK)))
comment_row = '/'.join(comment)
no_stop_words = remove_stop_words(comment_row.split('/'))
for word in no_stop_words:
if word in raw_new_words_hash_map:
raw_new_words_hash_map[word] = raw_new_words_hash_map[word] + 1
else:
raw_new_words_hash_map[word] = 0
jieba.add_word(word)
print('add new words finished')
new_words_hash_map = {}
for key_word, times in raw_new_words_hash_map.items():
if times >= sensitivity:
new_words_hash_map[key_word] = times
end_time1 = time.time()
print("cost " + str(end_time1 - start_time1))
append_corpus(new_words_hash_map)
def append_corpus(new_words):
corpus = set()
size = len(new_words)
for item in raw_corpus:
w = item.split(' ')[0]
corpus.add(w)
print(len(corpus))
for key_word, times in new_words.items():
if key_word not in corpus and len(key_word) > 2:
new_item = '\n' + key_word + " " + str(topK) # str(times/size)
print(new_item)
corpus_fp.write(new_item)
def text_to_matrix():
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
tf_idf = transformer.fit_transform(vectorizer.fit_transform(raw_corpus))
weight = tf_idf.toarray()
print(weight)
return weight
def dimension_PCA(weight, dimension):
pca = PCA(n_components=dimension)
X = pca.fit_transform(weight)
return X
def cluster_birch(X):
brc = Birch(n_clusters=None)
brc.fit(X)
return brc.predict(X)
if __name__ == '__main__':
# weight = text_to_matrix()
# print(len(weight))
# print(len(weight[0]))
# fwt = torch.tensor(weight)
fwt = torch.rand(1186667, 30)
U, S, V = torch.pca_lowrank(fwt, q=30, center=True, niter=2)
print(U)
print(S)
print(V)
# with open("U.txt", 'w+') as f:
# f.write(str(U))
# with open("S.txt", 'w+') as f:
# f.write(str(S))
# with open("V.txt", 'w+') as f:
# f.write(str(V))
|
数据模型过大,ubuntu 虚拟机基本上一跑就卡死,把真机上的内存杀手 chrome 也挤得够呛。VScode运行无响应,还是用命令行运行保险。
坑
我再也不用 Manjaro 了
Redis 迁移
127.0.0.1>save 后去对应目录下复制dump.rdb- 若不知道要复制 到|从 哪个目录,可用
127.0.0.1>config get dir获取
- 覆盖|粘贴
dump.rdb前一定要systemctl stop redis后ps -ef | grep redis看一下进程在不在,网上哪些用kill -9的杀死劲,不管用,杀了以后它换个 pid id 继续皮干。
sudo cp 一下,启动 redis,理应成功。
内存不够
unable to allocate gib for an array with shape
待了解原理???
numpy.core._exceptions.MemoryError: Unable to allocate array with shape 这个报错windows下改了虚拟内存,pycharm下相应的设置也改了,都没用。所以只能去linux上重新开始项目了。sudo -i 切换 root# 执行echo 1 > /proc/sys/vm/overcommit_memory即可。
换成 linux 环境后执行上述命令
Process finished with exit code 137 (interrupted by signal 9: SIGKILL
用 pytorch 分批训练
用 chunk 切分数据仍然不行。。。
估摸着是读矩阵一次性读到内存中后继续在内存中操作会使内存占用变大然后超过门限,torch.utils.data 虽然可以分批加载数据,但是从硬盘中读。
存到硬盘中一端端读
将数据以不同的方式取部分,最后形成多个模型。可以以人工根据这些模型的好坏评个分,然后以分数为权重进行决策。或之间都赋一个分。
linux 扩容内存,虚存
free -m 发现虚存不断扩大直到门限然后 killed 或 出现类似 RuntimeError: [enforce fail at CPUAllocator.cpp:65] . DefaultCPUAllocator: can't allocate memory: you tried to allocate 127392453696 bytes. Error code 12 (Cannot allocate memory) 的错误, 说明 内存虚存 分配的不够多
参考1,2, 在这里回答了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
# disable the use of swap
sudo swapoff -a
# create the SWAP file. Make sure you have enough space on the hard disk.
sudo dd if=/dev/zero of=/swapfile bs=1024 count=136314880 status=progress
# 输出:
# 139458259968 bytes (139 GB, 130 GiB) copied, 472 s, 295 MB/s
# 136314880+0 records in
# 136314880+0 records out
# 139586437120 bytes (140 GB, 130 GiB) copied, 472.372 s, 296 MB/s
# Mark the file as SWAP space:
sudo mkswap /swapfile
# 输出:
# Setting up swapspace version 1, size = 130 GiB (139586433024 bytes)
# no label, UUID=25a565d9-d19c-4913-87a5-f02750ab625d
# enable the SWAP.
sudo swapon /swapfile
# check if SWAP is created
sudo swapon --show
# 输出:
# NAME TYPE SIZE USED PRIO
# /swapfile file 130G 0B -2
# Once everything is set, you must set the SWAP file as permanent, else you will lose the SWAP after reboot. Run this command:
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
|
之后看虚存有没有吃上,有没有用完
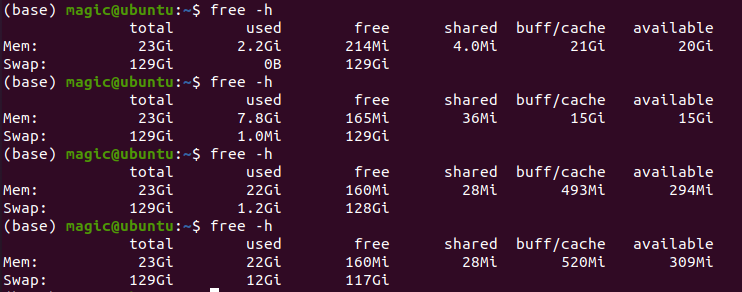
内存与CPU都成为速度瓶颈
前面的方法我都试过了,无奈数据集太大,就到了这里。
将原本几十万条数据取出1000条进行训练,还是到了这一步,也就是如果将数据分批计算的化到毕业我的毕设是做不完的。
如果租厉害的服务器又要花很多钱,又没得报销,坚决不干。
解决方案初步构想:
资源不够,算法来凑
那几十万维向量对应的词先自己分成n类,将维度降至n维,再对那n维进行PCA降维到m维(m <= n),得到几十万行(可不断增加,根据资源自适应) * m的矩阵,再进行聚类。
参数说明
bs= sets the blocksize, for example bs=1M would be 1MiB blocksize.
count= copies only this number of blocks (the default is for dd to keep going forever or until the input runs out). Ideally blocks are of bs= size but there may be incomplete reads, so if you use count= in order to copy a specific amount of data (count*bs), you should also supply iflag=fullblock.
seek= seeks this number of blocks in the output, instead of writing to the very beginning of the output device.
最终解决方案
遇到的问题是:以具体的词语构成向量的维度形成的稀疏矩阵数据规模超过了我的硬件和时间承受能力。
使用 LTP4 进行对自然语言的词性划分,将原本几十万维的具体的词语构成向量转变成以词性构成的低维向量,虽然降低了训练的精度,但是硬件可以承受。
Linux 空间用完不要关机,保存之前写的代码,再继续操作
快照不频繁,一夜回到解放前
再次划分任务(正在进行的工作,之后要做的实现的需求)
实现坑后需求
代码略,已开源致github
异常检测算法第二层
聚类
代码略,已开源致github
调参
自创感觉算法,区别于科学教徒的书本算法。举例:
下面这些评论,小爷我感觉它们有点傻逼,所以设置过滤值为5
下面这些评论,老子认为它们非常傻逼,所以设置过滤值为6
下面的评论我认为不怎么傻逼,所以设置过滤值为2
第二层过滤,是从另一个层面去搞的,粒度更细
比如过滤下面这种,毫无营养价值的评论(虽然看微博本身就没什么营养)
将网页评论传到后端
划分任务
js脚本抓取评论
选一个业务场景
选一个含微博评论的页面 https://weibo.com/5639089198/JE5k6rgXV?type=comment
分析源码
编写脚本
效果

前后端通信
前端送数据到后端
分为 服务端、油猴端,已开源
前后端交互
设计思路
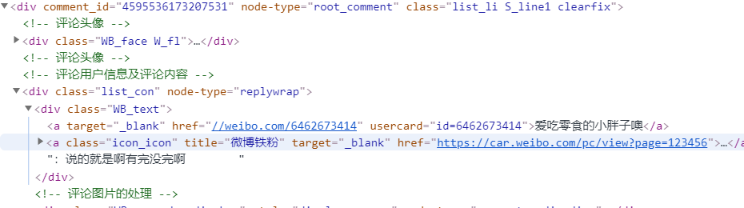
原从手机端爬的评论数据由键值组成,键由comment_id, user_id, url_id组成。而网页端的微博,which爬它的难度最高,评论的id若要找到user_id或url_id太繁琐,需要解析这种https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4621646001078652&from=singleWeiBo&__rnd=1617403583282

这种ajax请求的模式每隔一段时间会变一次,19年的和21年的就不一样。他们是有拿工资的员工不断更新这种请求模式的,防止别人一直爬它,我是一次性的,把它当作炫技的毕设交了,之后不去管它了。我又不看微博,而且还淡推了,现在连RSS都只是偶尔瞄一眼了。
所以现在把hash映射的模式改为:键是comment_id,值是评论的文本,其它字段用默认值填充。
打通 Node.js 和 Python 的任督二脉
练习
新开一个测试仓库,专门用作将所学的理论实践一下,见
https://github.com/magictomagic/learn/tree/main/src/node_python
博客
正在打算用ghost或加上React建一个迁移比较快的博客. 现在这里挖个坑.
效果
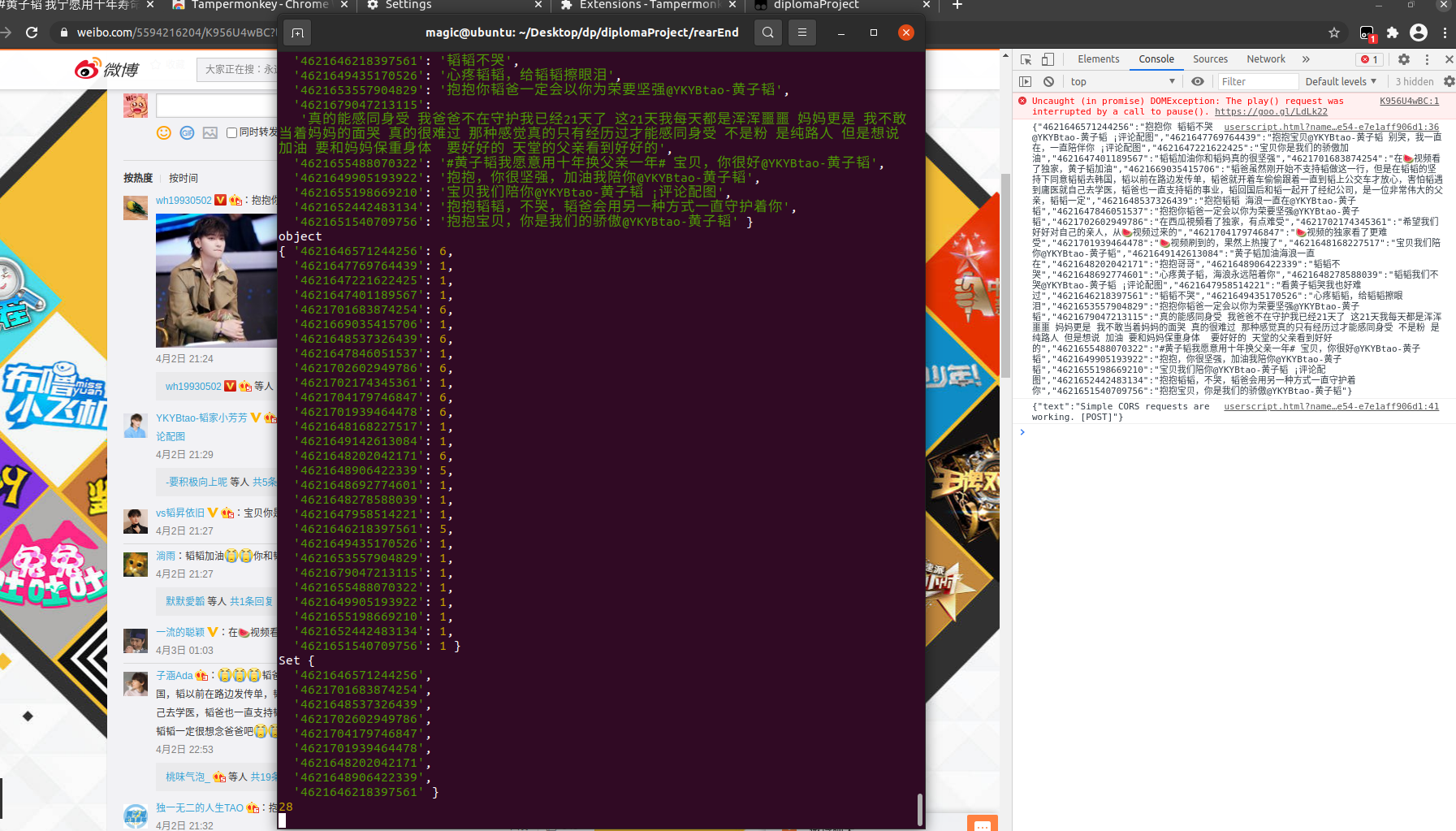
要删除的评论根据id以set返回
打通 Node.js 和前端的任督二脉
CI/CD 持续集成
Git Action
经验
- 将数据从网页上爬下来不要过分清洗,从而破坏原来的结构,要记录爬取每条数据时的时间。要在尽可能小的占用存储空间的基础上尽可能多的保存数据之间的关系。
- 能利用的资源(账号,IP,服务器~~,其实就是钱~~)越多,个人的潜力与才能才会得到更大发展。真的是马太效应啊!
- 框架或现有的设计模式 既是模板,也是束缚,束缚对应已经限定死的场景,稍微活一点的场景就要用本真屎山了。
- 本人日相属马,在未修相之前,与时相相害,与月相相冲,与年相相和。所以要谨慎得使用马属相。要善于将想法、思路,表达出来,切忌完美主义,被迷了路。每次先想到一个比较完美的解决方案后,想一想,做这件事的目的是什么,效果要怎样,如果砍掉其中某个花里胡哨的东西,用另外的简洁有缺陷的方案代替,大大缩短人月,效果也不差,是否更好。脑海中一定要有
目的, 能用就行两个声音。
- Pycharm 点击运行后自动加入当前工作目录路径于环境变量和当前文件路径。以cli运行python文件时不要用
os.getcwd这类取决于命令执行环境(路径)的函数,要用os.path.dirname(os.path.abspath(__file__))这类取决于文件位置的函数。
JSON.stringify doesn’t directly work with sets because the data stored in the set is not stored as properties.
But you can convert the set to an array. Then you will be able to stringify it properly.
Any of the following will do the trick:
1
|
JSON.stringify([...s]);
|