集中实习 推荐算法 我的工作
Contents
数据处理
进一步清洗
确保除去部分空白符,规整,去重,重命名爬取的数据。
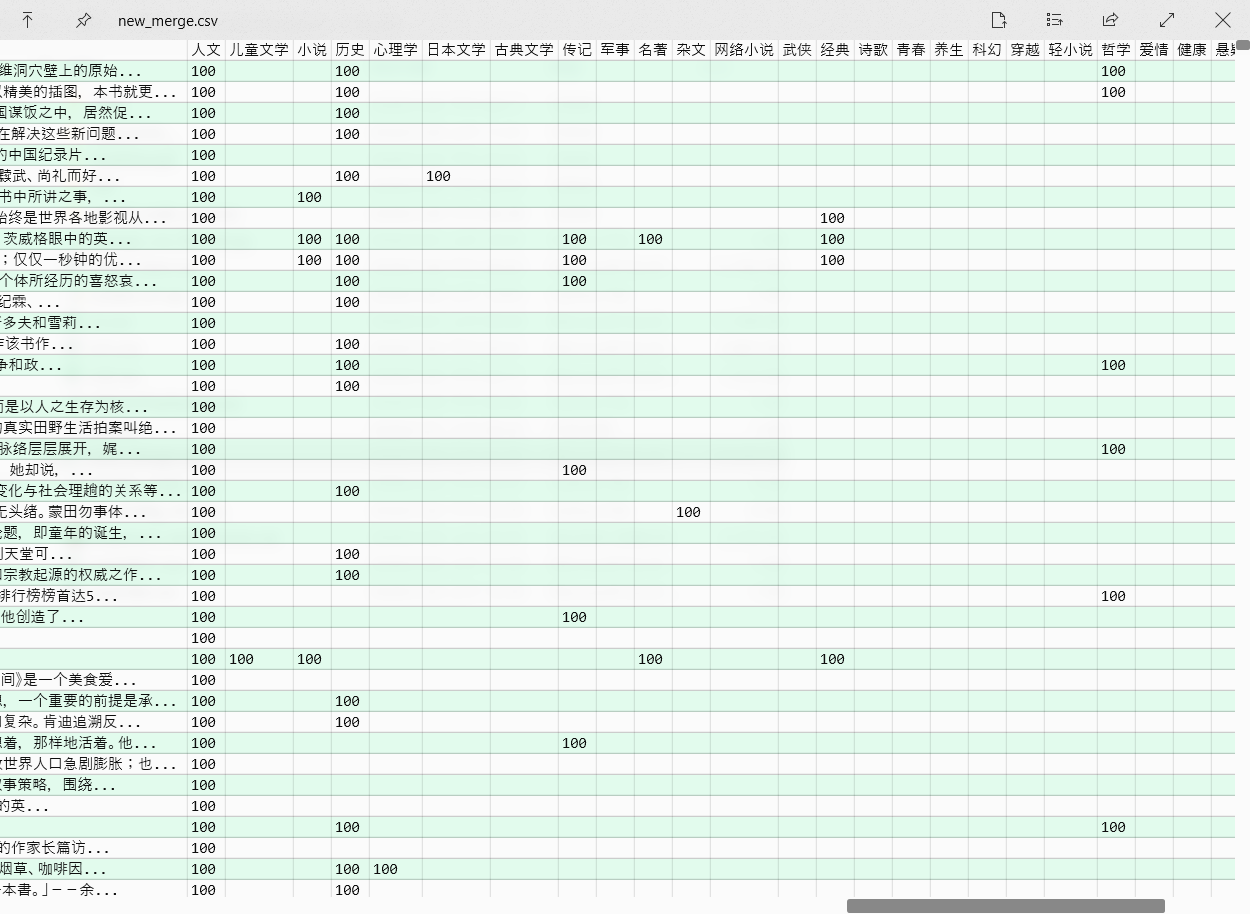
合并
将相同书名和作者但标签不同的书籍合并,多一个含 30 维标签的向量。

敏捷开发协同过滤算法
V1: 随机推送
V3: 基于书名推送
V4: 基于 id 推送
V5: 使用 numpy 优化速度
实现过程
-
算法选择
和某组员讨论使用什么算法,开始我只关注数据层面的,没有关注算法,在设计好了数据后,看了一眼算法,发现这是基于用户的协同过滤算法,可是我们没有初始的用户数据,但这个组员执意用基于用户的协同过滤算法。。。可能是这个代码是他网上找的,然后看也不看直接复制粘贴到 IDE 上,费了好大力气看懂,然后在我和老师的帮助下调通,然后觉得基于用户的协同过滤算法伟光正,不用这个算法就犯了路线错误,不能不用吧。总之,这种操作的起到的效果是:
1.选择的基于用户的协调过滤算法与我们组开始提出的需求极度不匹配,与前后端沟通失败。
2.浪费了 lz 两天时间,导致 lz 心情变差。
3.确立了自己写基于物品的协调过滤算法的方针。
-
敏捷开发
由于刚开始道路不够自信,所以我先实现一个简单的,就是V1版本,老师的评价是,如果这样,分数不会高,但称赞我掌握了敏捷开发的真谛。V1花了一上午时间,和前后端初步确立了 interface,加上被老师夸了,道路也更加自信了。
花了两天开发的差不多了后,和前后端进一步交流,确立了我返回的数据是一个书名的 List。
发现书籍会有重名,因为我一开始过滤是通过:书籍名 + 作者 洗与合并数据的,同一个书名的作者可能不同,比如《我的奋斗》,罗永浩也写了一本。所以把接口重新协商了。
之前的算法基本实现了图书推荐的功能,但主要存在两个不足。这个版本解决了之前的不足,如何解决放到亮点中了。不足点是:
-
推荐的书籍会重复。
-
每次计算推荐给用户的书籍要花上半分钟。
-
对应的原因是:
- 用户向量会越来越接近他所选择书的平均,导致其它差别不怎么大的书没有机会被选到,之前选过的书会经常出现在用户眼前。
- 使用迭代器遍历 .csv 文件,是一种顺序的遍历,效率低。
核心思想
找了好久才偷到了这些图
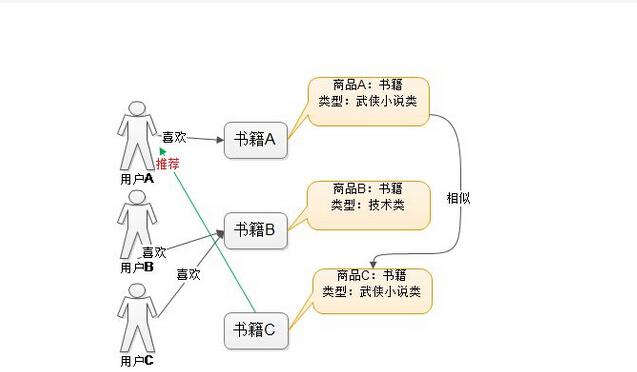

亮点
对照不足的原因,解决方案是:
-
增加一个存储用户喜欢与不喜欢的书籍的数据库(这里用 .csv 文件存)
-
使用 numpy,把书籍的每个标签当作一个向量,把用户的 preference 复制成和书籍的 dimension 一样,然后直接计算余弦相似度。获得余弦相似度向量,后续处理基本相似。跑一次 1.5s 左右,速度大大提升。