使用 OpenMP Pthread 实现高斯消元法
Contents
性能分析使用从系统获取时间的方法 由于是在虚拟机上运行,性能受主机负载影响。还会受温度等情况影响,不能保证性能分析的准确性
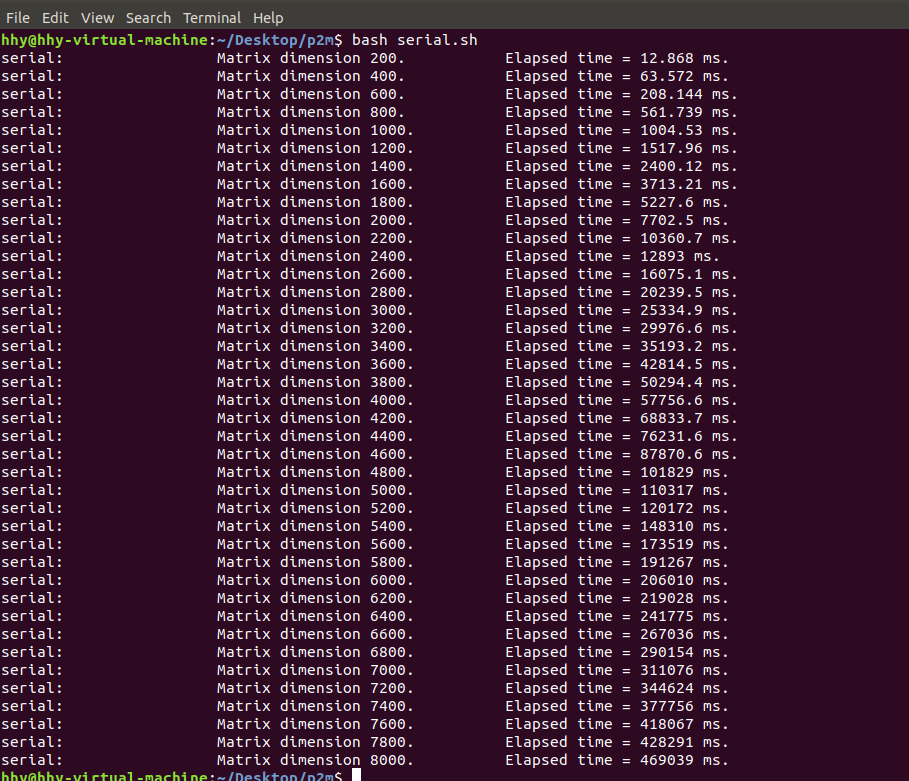
串行
思路:Forward Elimination,把矩阵变为倒三角形,Back Substitution,反向求出解。
代码:见附件
性能分析:见下图,还要与后面的性能分析对比着看
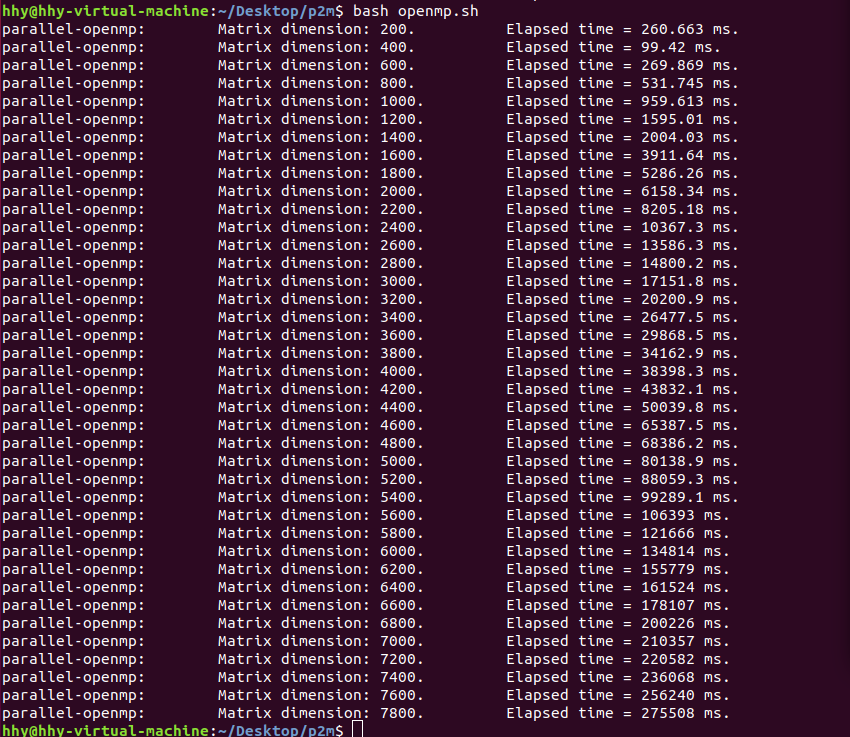
OpenMP
思路:仅在【计算三角形】,也就是 Forward Elimination 时,加一条 #pragma 语句,将内层原本循环一次生成一个“0”的部分并行化,但外层循环,Back Substitution 都不能并行化,因为存在数据依赖。
代码:见附件
性能分析:见下图,还要与前后的性能分析对比着看
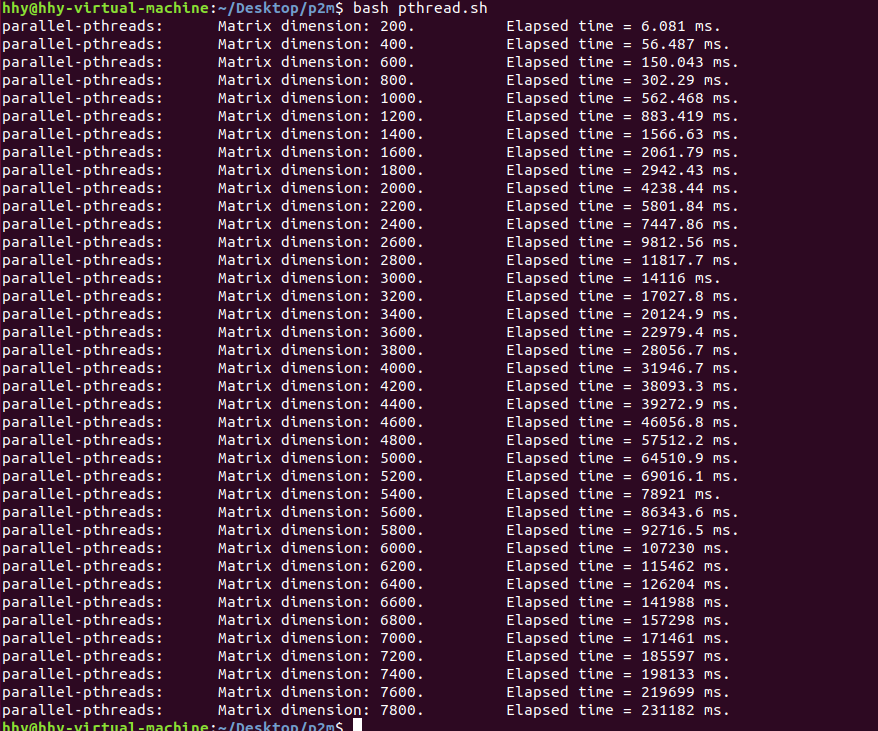
Pthread
思路:可并行部分与前面一样,将内层循环作为一个函数,每次创建一个线程就调用这个函数,也就是这个函数被 pthread_create 创建的线程调用,等每个线程将“0”算出,就把每个线程调用的函数之前申请的空间释放,然后将这个线程销毁。
代码:见附件
性能分析:见下图,还要与前后的性能分析对比着看
Pthread 改进版
思路:由于每次调用内层循环后都要把原来申请的空间释放,那么,能不能将这个空间到最后才释放,以减少频繁释放空间的开销,提高并行计算速度呢?将 param 设置为一个结构体数组,到最后才释放所有内存空间。理论上,在内存很大的情况下,这样操作可以提高数据处理速度;现实中,内存大小有限,在数据规模较小的情况下,性能提升,随着数据规模的增大,性能可能会因为内存耗损而下降。
代码:见附件
性能分析:见下图,还要与前面的性能分析对比着看
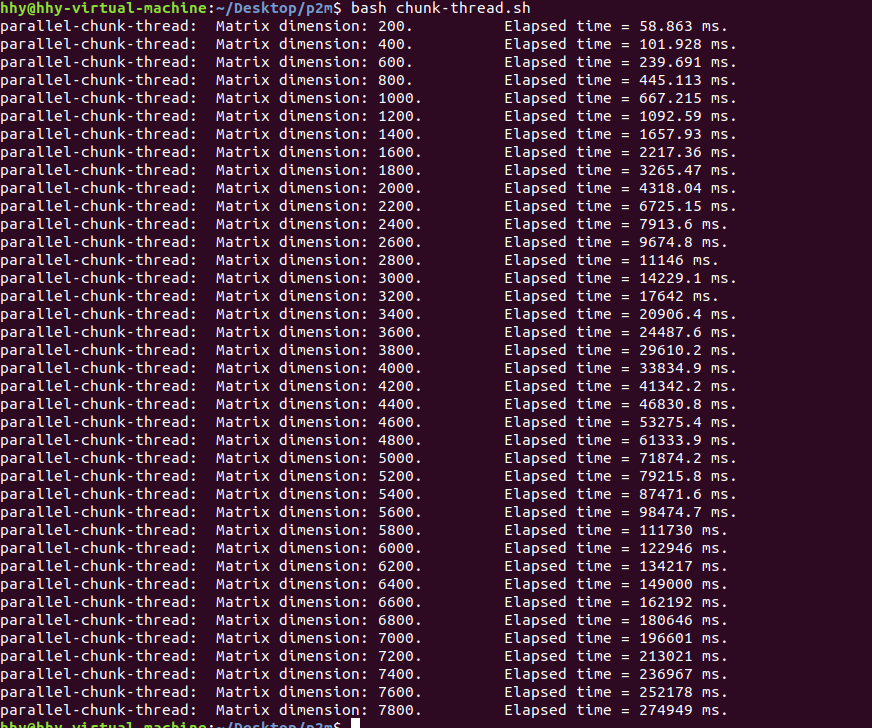
可以发现,Pthread 改进版的性能比原版差,而且是每个数据规模都比原版差。如果忽略其它影响因素,仅从理论上分析,可能是我的内存太小,导致前期申请结构体数据的开销不足以弥补不用释放的开销,后期内存耗尽的开销影响不用释放内存的开销。或者是前面的判断是错的,是我忽略了修改以后的算法中的某些细节。
附件:Makefile
自动化测试工具:串行, OpenMP, Pthread,chunk-Pthread