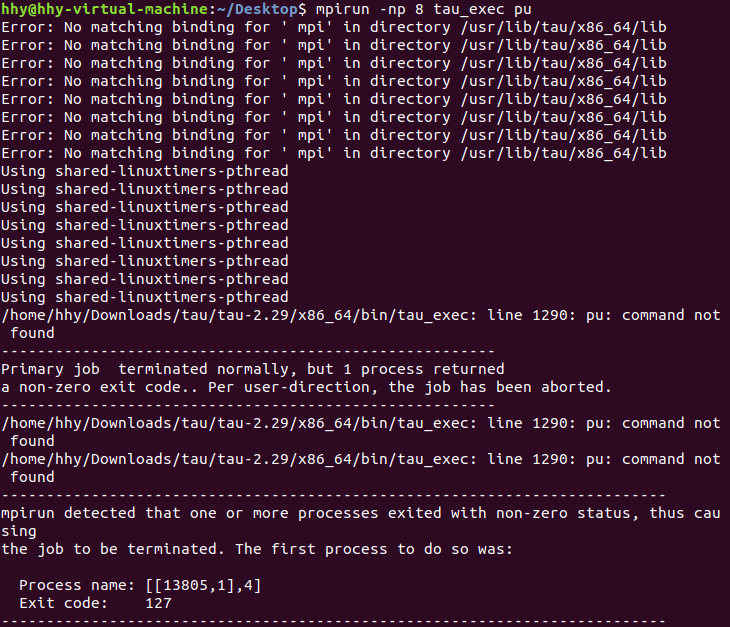
MPI experiment
Contents
串行版本
随机产生指定数据规模的矩阵 若不调用 MPI 函数感觉做对比实验不严谨,因为不包含 MPI 函数的开销。
代码见附件
并行版本
最原始的方法
思路:通过将数据量除以进程个数,将数据分为进程数个块,主进程对矩阵赋初值,通过 MPI_Send 将矩阵广播到各进程, MPI_Recv 接收数据,计算结果后,再发送给主进程。
实现:见附件
测试:见下图
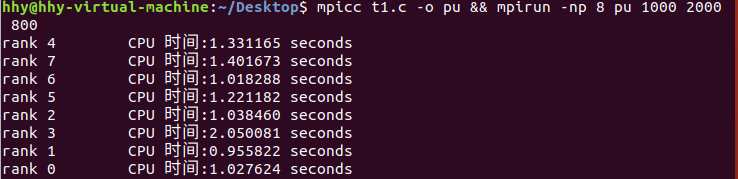
利用 MPI_Scatter 和 MPI_Gather
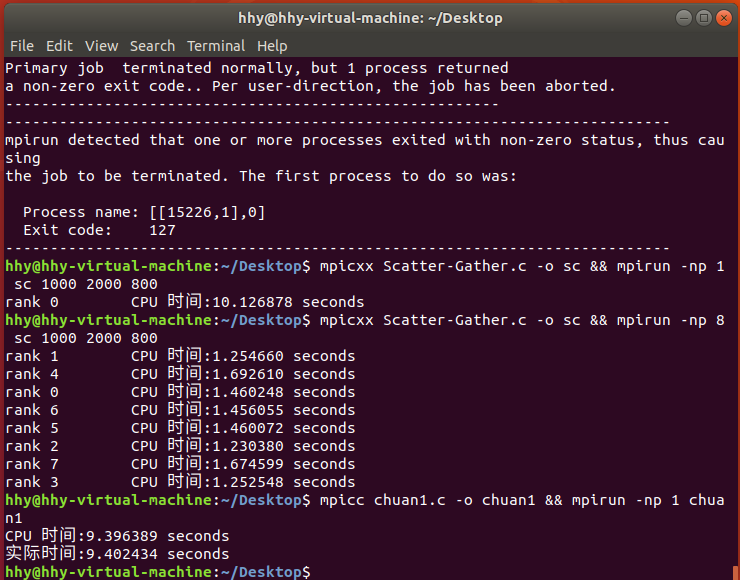
思路:先将矩阵 A 和 C 按行分为 np 块,进程号为 id 的进程读取 A 的第 id 个分块和 B;进程号为 id 的进程求解相应的 C 的第 id 个分块。
实现:见附件。
测试:调整数据规模为 1000 * 2000 * 800,既耗时不长,又可体现并行和串行的明显差异
利用 MPI_Send 和 MPI_Recv 代替 MPI_Bcast
参考教程
实现:见附件。
测试:增大数据规模,见下图
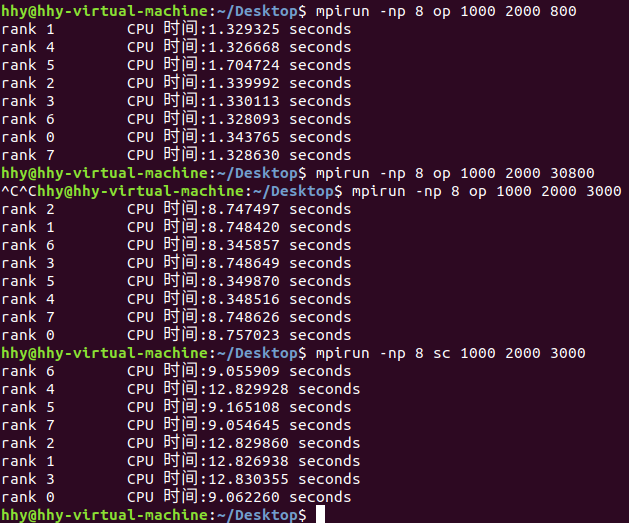 可以看到,数据量大时用重写的方法性能更好。
但就性能上说,实验结果与教程中的结论相反,不知道为什么。
可以看到,数据量大时用重写的方法性能更好。
但就性能上说,实验结果与教程中的结论相反,不知道为什么。
另外,性能分析工具莫名其妙报错了,我只能通过 clock() 来手动计算时间。